En este capítulo vamos a explicar en detalle qué es realmente la estructura web y cómo implementarla de forma óptima a nivel SEO. Y empezamos definiéndola, ya que habitualmente se confunde estructura web con estructura de urls, cuando son dos cosas completamente diferentes.
La estructura web (o arquitectura web) es la forma en la que se organiza el contenido de una web, independientemente de cuales sean las urls de cada contenido. Esta estructura tiene dos alcances: el primero, que abarca la organización del contenido dentro de una página, pantalla o url; el segundo es el que engloba toda la organización del contenido dentro de un dominio, subdominio o sección.
Tenemos que tener claro que estos dos alcances influyen directamente en la optimización onpage de una web, por lo que debemos conocer qué tipos de estructura benefician y cuáles perjudican al posicionamiento de una web.
El gran reto al que nos enfrentamos desde el punto de vista SEO es conseguir una estructura web óptima para posicionar los contenidos de la web, pero que esté alineada con las propuestas de otros departamentos que suelen estar presentes en la definición de esta arquitectura de la información, como son los departamentos de UX, IT y, obviamente, aquellos directamente ligados a producto y negocio.
¿Cómo tiene que ser una estructura web SEO Friendly?
Para que una estructura web se considere SEO Friendly debe facilitar el rastreo y el acceso a la información a los crawlers de los distintos buscadores. Para ello, lo primero que debe garantizar nuestra estructura web es que todas las urls que contienen información susceptible de ser indexada, estén enlazadas adecuadamente. Además, la estructura del contenido dentro de cada url debe permitir que el contenido esté disponible de forma visible sin necesidad de interacción alguna por parte de los usuarios, ya que los bots de los buscadores nunca harán click o lanzarán eventos de ratón, como “mouse over”.
Antes de decidirnos por una estructura web, debemos tener claro cómo afecta al enlazado interno de la web. Otro punto a tener en cuenta de cara a definir una estructura web es el contenido duplicado y thin content (contenido de escaso valor) que genera, ya que esto puede ser el principal problema SEO que tenga nuestra web si no lo resolvemos adecuadamente, muy especialmente en sitios webs con muchas urls.
¿Cómo estructurar la información en una web?
La forma de organizar los contenidos de una web nos permite catalogar a las webs en tres grandes grupos, las que categorizan todas su información de forma exhaustiva en taxonomías, las que lo hacen de una forma más caótica agregando sus contenidos en grupos de contenidos relacionados o clusters y las que utilizan una mezcla de ambos. Veamos las particularidades de cada uno:
Basada en taxonomías
Este tipo de webs son aquellas basadas en una categorización clara de la información, como pueden ser los blogs, con taxonomías basadas en categorías y en etiquetas, o muchos ecommerce, los cuales agrupan sus productos en categorías y subcategorías a distintos niveles.
En este tipo de webs el problema suele estar en las taxonomías secundarias, como las tags de los blogs o medios de comunicación, las cuales si no están claramente editorializadas o no se controla su indexación, pueden generar gran cantidad de contenido duplicado.
También son susceptibles de generar estos problemas el uso de jerarquías que aparezcan simultáneamente en varias taxonomías, así como los productos o artículos que se catalogan en múltiples categorías, por lo que en este tipo de estructura web se aconseja prescindir de indicar en la url la categoría a la que pertenece dicha url. Recuerda que estructura web y estructura de urls no son lo mismo y te ahorrarás muchos problemas (y redirecciones innecesarias).
Clusters de contenido
En este último apartado se encuentran los grandes sites de Internet (y que lideran también los rankings SEO) como son Wikipedia, la mayoría de portales de clasificados y algunos grandes ecommerce. Este tipo de arquitectura destaca por su gran cantidad de enlazado interno y una presencia mínima de menús.
La gran ventaja de esta estructura es que agrega a los contenidos por su relación temática entre sí, lo que es ideal para que los buscadores hagan bien su trabajo. El problema: requiere de un control férreo que evite los duplicados cercanos (contenidos muy similares entre sí) y de unos redactores que tengan claro cómo y a dónde deben enlazar.
Búsquedas indexadas
Pese a que es una práctica desaconsejada por Google, la realidad es que bien implementada es una estructura ideal para atacar las búsquedas longtail. El punto negativo es que necesita una supervisión y estrategia SEO muy bien definida para evitar que se convierta en una estructura con contenido duplicado casi infinito.
En el fondo es un híbrido entre las dos anteriores, ya que se basa en una estructura jerárquica de taxonomías en los primeros niveles combinados por clusters de contenido que se obtienen a través de un buscador.
Ejemplos de webs que utilizan esta estructura son Milanuncios, Amazon o Idealista.
Para poder posicionar con éxito una web así, se debe controlar muy bien qué búsquedas deben indexarse y, más complicado aún, cuáles y dónde deben enlazarse. Por tanto, si no estás acostumbrado a estructuras webs de este tipo, no es recomendable que la utilices.
¿Qué elementos definen la estructura web?
De cara a definir la estructura de una web, contamos con los siguientes elementos a nivel de página:
- Menús
- Breadcrumbs
- Filtros
- Listados
- Relacionados
- Paginación
Los elementos más conflictivos a nivel SEO son los filtros, listados y la paginación, ya que si no los controlamos son los grandes generadores de contenido duplicado y thin content. Normalmente los SEOs recomiendan evitar el rastreo o la indexación de estos, aunque bien utilizados (sobre todo los filtros) pueden ayudarnos a conseguir posicionarnos en búsquedas longtail. Por eso, vamos a analizarlos en detalle:
Listados
Imprescindibles en la mayoría de webs, excepto en aquellas tan pequeñas que sus principales secciones quepan en un menú, los listados y sus elementos de filtrado (facets) y ordenación tienen que estar muy acotados a nivel SEO.
Paginaciones
El uso de la paginación también es un factor de claro impacto en la estructura web y en el rastreo por parte de los bots de los buscadores.
Debido a que muchas veces el contenido de las páginas de un listado es muy similar entre sí, especialmente en ecommerces y webs de clasificados, las páginas internas suelen ser un problema para el posicionamiento web. Esto quedó claro a la comunidad SEO tras la confirmación por parte de John Muller de Google que no están teniendo en cuenta las etiquetas HTML que deberían utilizar para entender correctamente los listados paginados: las etiquetas link rel=”next” y rel=”prev”.
Por tanto, hay que tener en cuenta que cuantos más listados paginados tenga un sitio web, mayor serán los problemas de rastreo y le será más complicado a Google indexar y posicionar adecuadamente las páginas.
En el extremo opuesto tenemos el problema de que si la web dispone de muchos elementos (productos o anuncios, entre otros) sin una
paginación de listados es muy fácil que estos puedan quedarse sin ningún enlace interno apuntando hacia ellos, con lo que esto supone para el posicionamiento.
Las estrategias SEO más eficaces para evitar estos problemas, sin cambiar la estructura de la web, son dos, en función de si nos interesa posicionar los elementos del listado o no:
- Scroll infinito: solución ideal cuando no necesitas posicionar los elementos paginados, ya que deja sin enlazado interno a todos los elementos que no aparecen al cargarse la página y sin interacción por parte de los usuarios. Es importante destacar que el uso de este tipo de paginación colisiona con el uso de un footer en los listados, ya que en este tipo de solución no es posible hacer click en los elementos del footer al ir añadiéndose al hacer scroll nuevos elementos que lo desplazan.
- Aumentar el número de elementos de cada página: en el caso de que tengas que mantener la paginación y quieras mantener enlazados todos los elementos de los listados, esta es la solución que te interesa. Es habitual ver webs donde solo se muestran 9 elementos por página (o incluso menos) y que tienen listados de más de 5 páginas, lo cual complica la arquitectura de la información añadiendo urls innecesarias. Si se aumenta el número de elementos por página a un número que no suponga un problema para el rendimiento de la web o su tiempo de carga (y tampoco para la usabilidad de la web), conseguiremos reducir drásticamente el número de urls de la web evitando o aligerando los problemas de rastreo comentados.
¿Cómo hacer una estructura web adecuada en base a la paginación?
Lo primero que tienes que preguntarte es si de verdad necesitas una paginación o si es realmente necesario que esa url deba ser un listado paginado, ya que muchas veces por inercia definimos estructuras web en la que cada solo hay listados y productos (o artículos, anuncios, etc.) cuando existen otras opciones más adecuadas a nivel SEO.
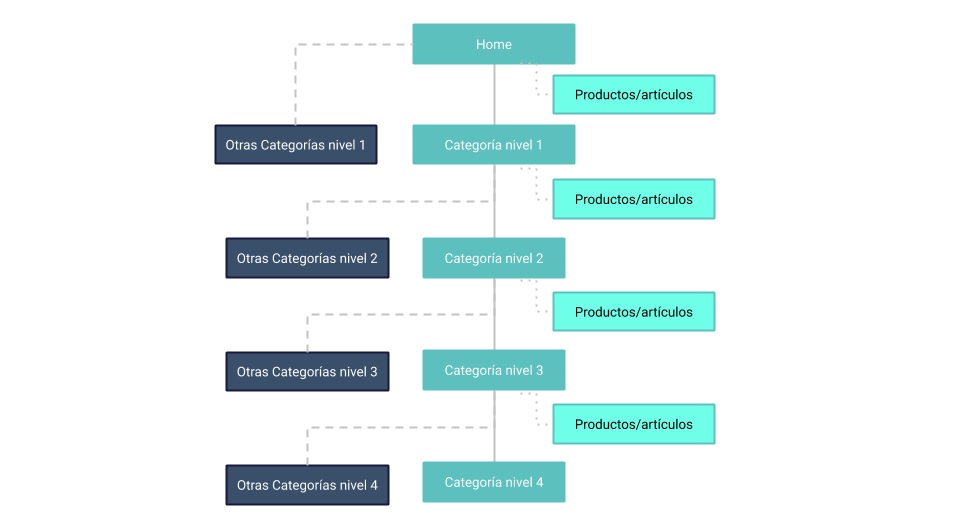
Para facilitar la comprensión de esto, observa los siguientes gráficos con estructuras web simplificadas. El primero muestra una paginación en todos los niveles de la web desde la portada, mientras que el segundo carece de paginación:
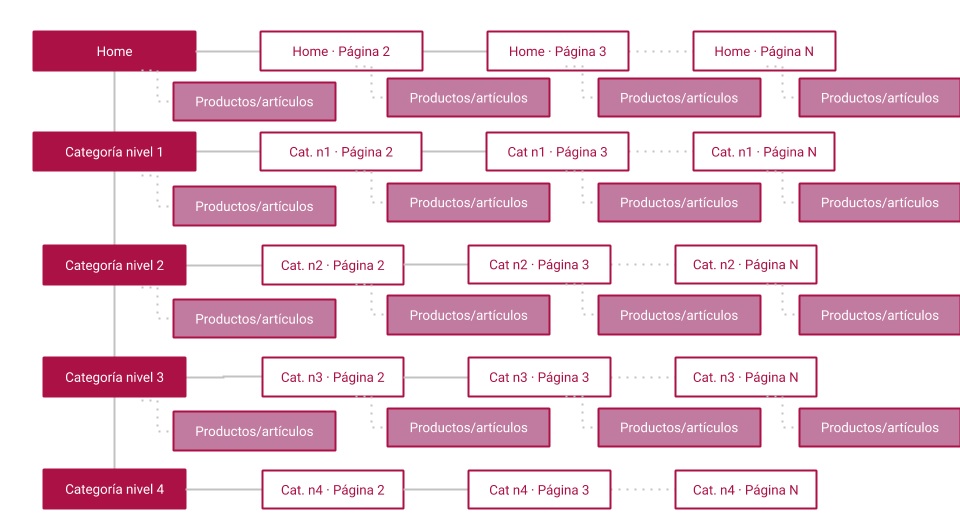
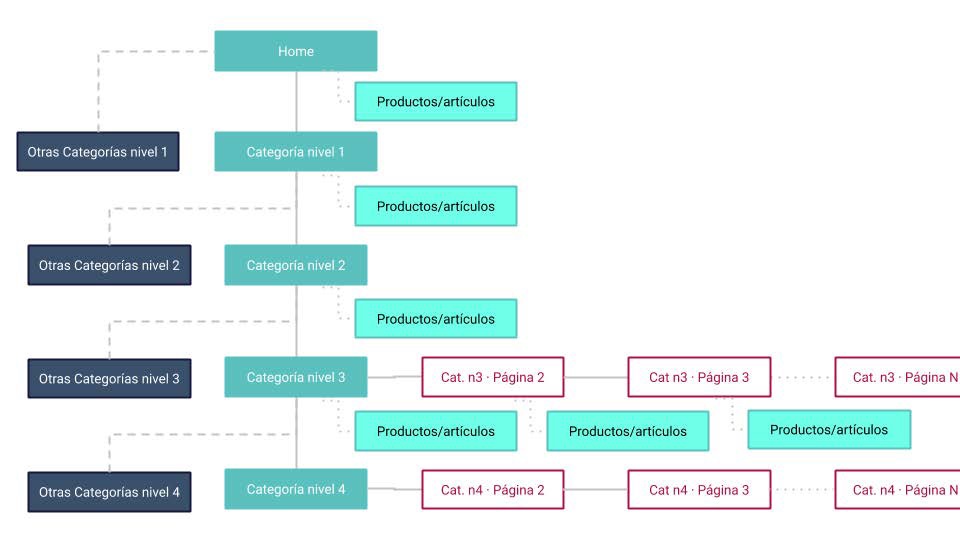
Es evidente la menor complejidad de esta opción en la que con mucho menos espacio se han podido incluir elementos interesantes a nivel SEO, como lo son otras categorías del mismo nivel de las representadas en ambos gráficos. Eliminar la paginación nos permite que los crawlers profundicen en la estructura hacia contenidos muy relevantes en lugar de perderse lateralmente.
Como en muchas ocasiones no es viable eliminar del todo la paginación, lo mejor en estos casos es incluirla lo más abajo posible en la estructura, idealmente en el tercer o cuarto nivel de la taxonomía: