
Cómo conseguir que Google indexe (bien) y rastree (bien) nuestro sitio web
¿Te has preguntado alguna vez cuántas URLs conocerá Google de tu página web? Tal vez te hayas sorprendido oyendo a algún SEO diciendo que no son necesarios los sitemaps ¿verdad?. ¿Te has peleado alguna vez con un robots.txt? Todo esto tiene que ver con el concepto de indexación.
Para que los contenidos de nuestras páginas webs sean mostrados en los resultados de búsqueda de los buscadores primero deben ser incluidos en su índice.
Este índice es como el de una gigante biblioteca, donde los libros están ordenados en inmensas estanterías y repartidas por todo el sistema y que, para acceder a alguno de ellos, primero debes saber dónde está.
Ahí es donde entra el índice, que es lo que el buscador guarda de tu página: una URL, una temática, la relación entre otras URLS (otros libros), las fotografías que hay dentro… de tal manera que cuando le preguntas: “libro de ficción histórica donde un castellano delgado y medio loco lucha contra molinos de viento” el índice te devuelve “El Quijote” de Miguel de Cervantes.
Si el buscador no conoce el interior de tu libro no puede ofrecérselo a quien lo busque ¿verdad? Por eso es tan importante que favorezcamos la indexación de nuestro sitio web. Vamos, que se lo pongamos fácil a los buscadores.
Qué es la indexabilidad
La indexabilidad se puede definir como:
- La facilidad con que los buscadores te encuentran
- La corrección de rastreo de todos los contenidos
- La identificación del contenido con las categorías y las intenciones de búsqueda del usuario.
Los buscadores en general (y Google en particular) no tiene problemas en rastrear cualquier fichero pero, cuando hablamos de indexación. (y, sobre todo, de rankeo en las SERPs), debemos centrarnos en los ficheros HTML de nuestra web, ya que son los que puede interpretar de manera más sencilla. ¿Podemos encontrar rankeando en las SERPs normales PDF? Por supuesto. E imágenes. Y otros ficheros.
Los buscadores no actúan como un navegante, como un usuario normal que navega en nuestra página web. Los rastreadores ven el código fuente y, cuando van a darle las características relevantes para su índice, simulan ser un usuario para intentar verlo como ellos.
La importancia de centrarnos en elementos HTML, que el rastreador pueda leer de manera sencilla, es clara. El crawler no sabe rellenar buscadores internos, no sabe enviar un formulario, no sabe clicar en algo que no sea un enlace, no es capaz de leer.
Sin embargo el buscador rastrea (o lo intenta) para mejorar su índice cualquier cosa que parezca una URL.
Cómo trabajan los buscadores
El rastreo es un proceso secuencial que va dando pasos, uno tras otro, donde todo empieza en descubrir y priorizar.
El objetivo de la araña del buscador (crawler) es descubrir nuevas URLs y leer lo que hay dentro de estas. ¿La forma de descubrir nuevas URLs? Los enlaces. Un enlace con código es la manera más eficiente de que el buscador las encuentre ¿Hay más? Sin duda, pero la manera en la que mejor podemos atacar la indexación de nuevos contenidos es
ponerle un link.
Y el algoritmo se permitirá el lujo de priorizar entre diferentes URLs, dependiendo de cual considere que es la importante de cada sección que haya descubierto.
Esto es así porque los algoritmos tienen más archivos en la cola de rastreo que recursos asignados (o disponibles) para indexar. Es por ello que sitios webs más importantes tienen una mayor cuota para permitir que la indexación de éstas sea más extensa que las de otros sitios menos importantes. Sitios webs con una frecuencia de actualización alta suelen estar asociados a una mayor indexación de sus urls. Lo mismo pasa en sitios muy enlazados o con una gran relevancia.
Indexación y rastreo no es lo mismo
No es lo mismo que una URL esté indexada que una URL rankee. La araña puede encontrar la URL y el buscador puede tenerla en su índice pero puede ser que no rankee (que se la pidas a google y no la muestre).
Esto es debido a que una puede estar indexada y sin rastrear su contenido o indexada y conociendo su contenido.
Una URL puede llegar a rankear por una keyword cuando:
- La entidad de búsqueda coincide con las entidades de las que se habla dentro de
esa URL - La URL está linkada (interna o externamente) y el link graph (el anchor text que enlaza a esa URL) tiene sentido temático con el n-grama que hemos buscado.
Indexación y crawleo no es lo mismo
No es lo mismo que una URL esté indexada que una URL esté rastreada (o crawleada). La araña puede crawlear una URL (es decir, saber dónde está) y no estar indexada. ¿Entonces para qué la crawlea? Bueno, esa URL puede ser indexada en el futuro. Una URL crawleada y no indexada es aquella que:
- El rastreador puede acceder a ella (sabe
dónde está) - El rastreador ha leído la URL (sabe qué hay dentro) pero
- El buscador decide que no la va a incluir en su índice (de momento o
para siempre).
Crawl budget, crawl demand, crawl rate limit
Conceptos muy entremezclados y complicados de separar ya que no existe una definición única para ellos. Simplificando (mucho):
- El crawl budget es el número de páginas que el buscador rastreará en tu sitio web.
- El crawl rate limit es la frecuencia máxima de peticiones de recuperación de información (en conexiones paralelas simultáneas) y el tiempo que tiene que esperar entre las peticiones. Esta frecuencia puede variar para un mismo sitio web en función de la capacidad del servidor para aceptar todas las peticiones del rastreador de google (así, servidores más optimizados o más potentes podrán tener un límite mayor).
Gary Illyes, en el post que escribió en el blog de de webmasters de Google avisa que, en sitios webs pequeños (< 2000 páginas y con poca frecuencia de actualización) esto no debería ser un problema.
Por qué es importante la indexabilidad
Respuesta corta: Si no se indexa no puede rankear.
Respuesta larga: Google debe conocer lo máximo posible tu web, conocer su contenido y la relación entre las diferentes secciones. Cuanto más enlazada esté una determinada sección más importante será y si una sección no está enlazada lo más normal es que esa parte de la web no tenga fácil el posicionamiento ya que luchará contra otras URLs que tendrán mucha relevancia por el número y la calidad de los enlaces entrantes. Os pongo un ejemplo. Imaginad que tenemos dos URLs, A y Z, con el mismo contenido (y que el buscador podría rankear ambas). Si la URL A recibe 1 link y la Z no recibe ninguno será la URL A la que rankee por encima.
Y sí, la indexación tiene mucho que ver con el ranking. Pero indexación y rankeo no es lo mismo, no lo olvidemos nunca.
Cómo facilitamos la indexación
Para facilitar el rastreo y la indexación de las URLs es imprescindible prestar especial atención a lo siguiente:
- Contenidos: El contenido debe, primero, ser relevante y segundo, no debe estar accesible en 2 (o más) URLs diferentes de nuestra web (o de otros sitios webs).
- Links: Debemos enlazar correctamente aquellas URLs más importantes de nuestro sitio web en zonas destacadas (normalmente, los menús de la web, breadcrumbs o bloques de links). Además, debemos controlar el número de links que ponemos en cada una de las URLs (para evitar que el linkjuice se diluya entre muchos enlaces).
- Lenguajes de programación: Debemos usar lenguajes de programación no intrusivos y evitar aquellos que requieren de un esfuerzo mayor por parte de los buscadores (por ejemplo, lenguajes como javascript y frameworks como Angular JS complican muchísimo el rastreo de las URLs y la indexación de sus contenidos).
Sitemaps
¿Qué hacemos cuando nos perdemos en una ciudad? Miramos el móvil ¿Y si el móvil no tiene batería? Sí: le preguntamos a la gente con la que nos encontramos o recurrimos a un mapa (bastante común en el metro, por ejemplo).
Los mapas de los rastreadores son los sitemaps en formato xml o html. Estos ficheros pueden formar parte de nuestro sitio web si decidimos ponerlos.
Estados por los que pasa una URL
estados de una URL dependiendo de su situación en indexación o no:
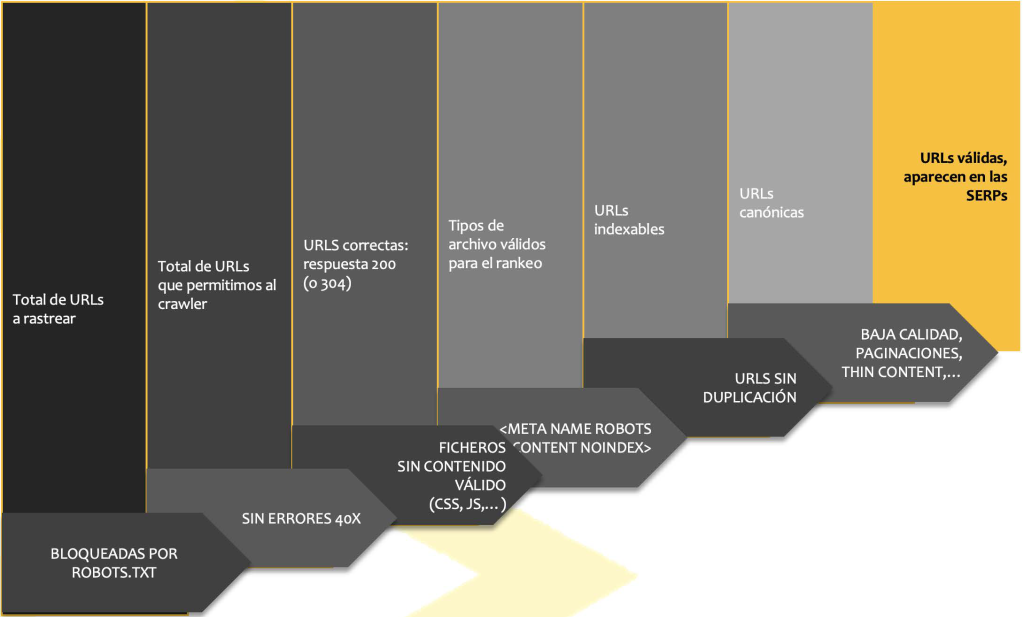
Las URLs candidatas para ser indexables y aparecer en las SERPs son aquellas que:
- Tienen calidad
- Son canónicas (o google las considera canónicas)
- No presentan duplicados
- No están bloqueadas por el meta robots
- Son ficheros válidos HTML (no CSS, no JS,…)
- Tienen una respuesta correcta 200 (no 400 o 30x)
- No están bloqueadas por el robots.txt
Por qué el buscador decide no incluir nuestras páginas
Normalmente, un buscador debería añadir todas las páginas descubiertas de un sitio web a su índice pero hay algunos casos en los que esto no será así:
- Contenido duplicado: si un buscador detecta que el contenido de una URL es muy similar a otras URLs del mismo sitio (o de otro sitio) podría decidir no indexar todas, sino aquellas que considere más importantes. Deberíamos prestar atención también: a los parámetros de las URLs que devuelven un contenido prácticamente idéntico y los conocidos como infinite space, páginas con un contenido irrelevante para indexar.
- Contenido débil o de baja calidad: Igualmente, si encuentra que el contenido de una URL es escaso o poco interesante (o diferencial). En este punto debemos prestar atención a los errores soft 404 o la navegación por facetas incorrectamente programadas.
- Canonicals: Las URLs en las que existan canonicals a otras URLs (o aquellas en las que el buscador decida que están incorrectamente canonicalizadas).
- Bloqueo en robots: Si el buscador encuentra que una URL está bloqueada en robots.txt o en la etiqueta.
- Tecnologías opacas: Carga de contenido sobre la misma web mediante tecnologías AJAX, angular.js, react.js, javascripts o similares es el problema más reciente en temas de indexación.
- Páginas hackeadas.
- Errores de servidor: Errores 40x, errores de servidor 50x o respuestas 30x pueden hacer que esas páginas no se indexen en Google.
- Splash pages, muros de registro o muros de contenidos: Los más conocidos, estos últimos, lo usan, sobre todo, los medios para mostrar su información sólo a usuarios registrados pero el mismo problema suelen tener aquellas webs que son solo para adultos o tienen restricción de edad (como las webs de bebidas alcohólicas que, en España, son para mayores de 18 años).
- Buscadores internos: Tener un buscador interno no es malo, pero que las URLs sólo estén accesibles vía buscador si es incorrecto ya que no permitiremos el descubrimiento de los contenidos.
- Frames e <iframes>: aunque antiguas, estas tecnologías siguen vigentes por la permisividad de la mayoría de redes sociales, que permiten la integración de una actualización o un estado dentro de las páginas webs. Estas tecnologías suelen ser bastante bloqueantes (aunque no siempre) para la indexación de los contenidos.
- Flash: tras ímprobos esfuerzos por entender qué había dentro de las webs en flash se ha terminado por dejar de soportar.
Terminando
Si quieres estar MUY informado del estado de indexación de tu sitio web te recomiendo que lo registres dentro de Search Console ya que su informe de cobertura es de lo mejorcito que puedes tener (sin tener conocimiento de logs y programación). En él puedes comprender de una mejor manera cómo está google navegando por tu sitio y qué piensa sobre él.
A modo de cierre busca una máxima: que el buscador solo tenga acceso a aquellas URLs importantes para el posicionamiento y no le hagas perder el tiempo en URLs inútiles. Mantén tu sitio sano. Su posicionamiento te lo agradecerá.